I recently started biking, and the fact that I’ve kept at it is due in no small part to Strava. I really like tracking my progress, seeing how I compare to others and myself. I’ll admit on more than one occasion, I’ve chosen to ride just to see those weekly numbers tick up.
My obsession with stats can obviously only be sated with more stats. After putting in the time on long rides, I pore over each segment seeing how my performance stacked up from week to week. Today, I went on a long ride (~37 miles) going up Montebello road and then down Page Mill. I huffed and puffed, facing cold rain atop Black Mountain, a sore elbow and unhealthy wobbles descending on the dirt road that almost ended with me eating shit. Yet I was happy to do it all so I could see my stats.

Then the terrible occurred – when I went to upload the file, nothing appeared in my feed. I waited … then waited some more … and then some more. It still wouldn’t appear! I tried recording another activity just to make sure I was able to upload files and it recorded just fine. Mortified, I thought my three hour suffer-fest would end with nothing to show for it (because in reality, what’s the point of riding without obsessing over times?).
Disclaimer: To be fair, I’m not sure I waited the entire time for my file to upload (it was pretty big, around 2.9 MB, and speaking of which Strava, I highly suggest you compress the files before upload, it would make them so much faster to upload), but still I thought that it was just taking the Strava servers some time to process.
However, it turns out that after a little digging in, I was able to recover the file and successfully upload it to Strava’s servers. Here’s the process to do so, so your precious activity doesn’t go uncollected.
First some context:
I have an iPhone 6 plus, running iOS 9.3.2 and Strava v.4.16.0 (4015).
Steps:
1. First, make sure the file is still on your mobile device. On the iPhone, you can connect your phone, open up iTunes, and navigate to Apps/Strava where you can see all of your activities. Here’s what it looks like:
Note: If you don’t have this file anymore, unfortunately I think you’re hosed. You can always try to contact Strava to see if your file is on their server somewhere.
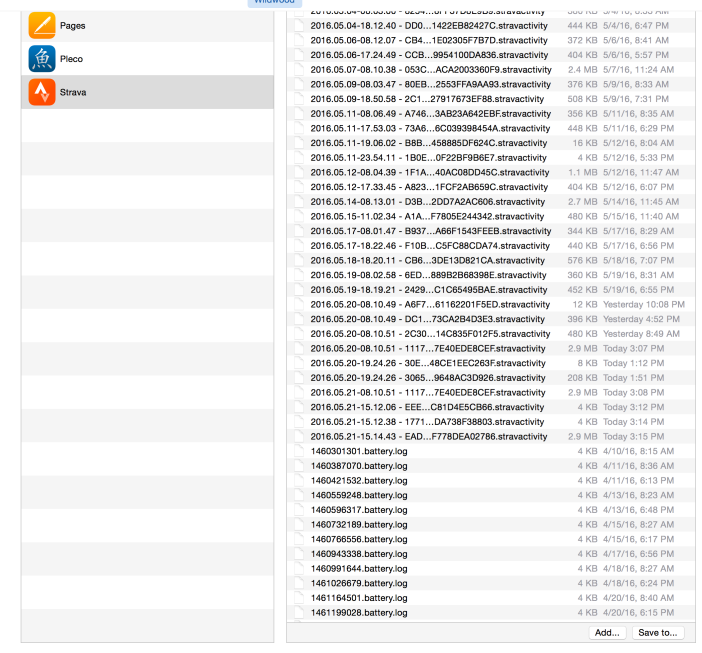
2. Next, locate the file that failed to upload to Strava. This may take a little bit of guess and check, however if it’s your latest activity, you’ll see it sorted by timestamp so it should be at the end:

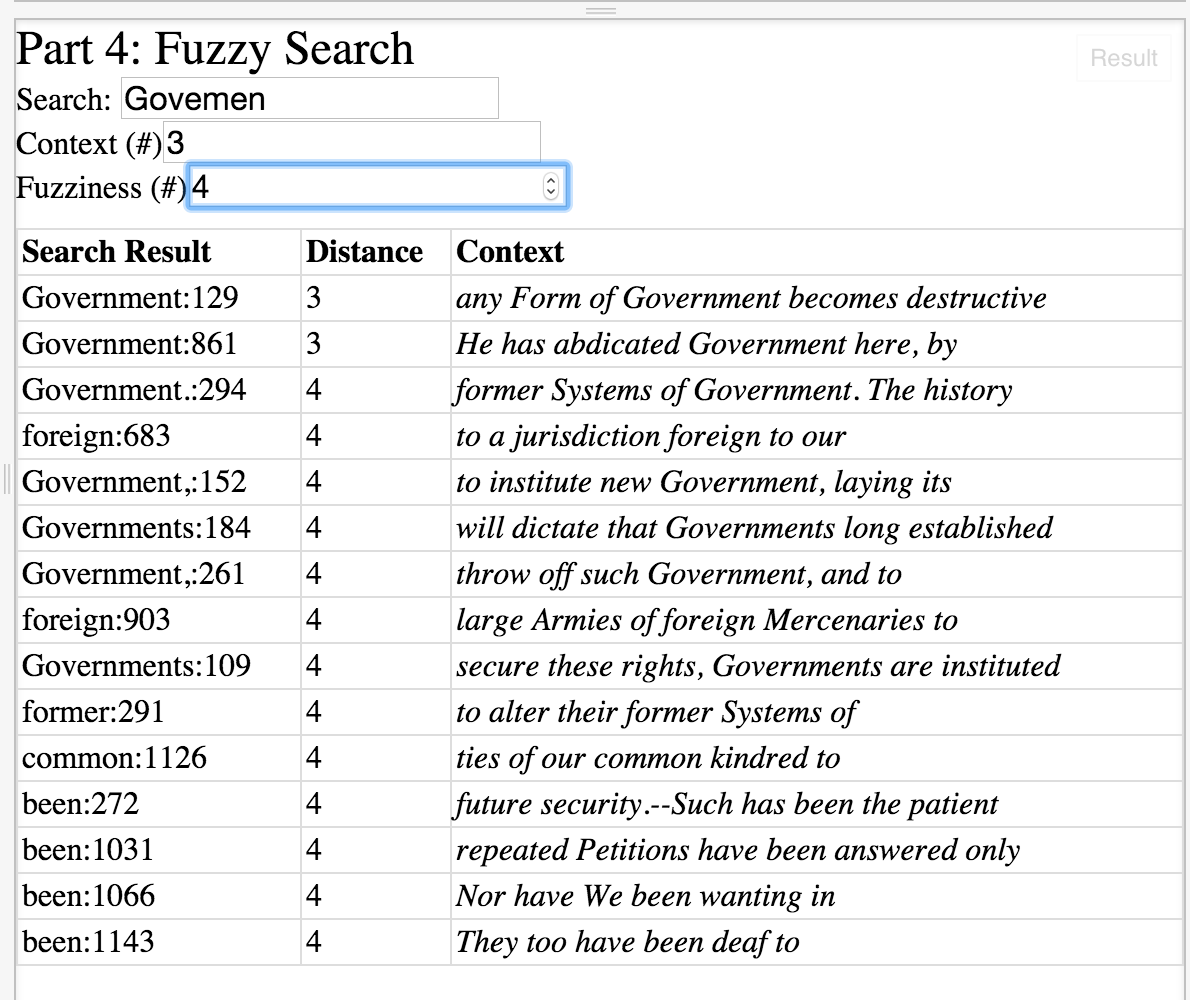
3. The next part is a little tricky. You can save the file to your local machine by right-clicking “Save to…”. And then you can open the file in a text editor. I used sublime text (hey I’m a dev). The file will be huge and looks something like this:
Sample file:
strt: t:485449851.286994
lvseg: t:485537646.134324 on:1
wp: lat:37.337964; long:-121.979434; hacc:5.000000; vacc:3.000000; alt:38.173744; speed:3.720000; course:268.593750; t:1463844846.142122; dt:1463844846.142122; dist:7.644818
wp: lat:37.337964; long:-121.979434; hacc:5.000000; vacc:3.000000; alt:38.173744; speed:3.720000; course:268.593750; t:1463844846.142135; dt:1463844846.142135; dist:7.644818
relv: v:0.977640; t:1463844846.825438;
Side note on understanding the file. I don’t work for Strava, so I’m just spitballing here, but the file is obviously appended to as your activity takes place. Here are some guesses as to what each datapoint means:
strt: looks like start
- t: unsure. At first I thought timestamp, but the value is way too low (resolved to somewhere in 1985). So still a mystery.
lvseg: looks like live segment
- given that strava just added this, I’m going to guess that this means you’re doing a live segment and on: 1 means it’s recording
wp: looks like these are the main data points
- lat: latitude
- long: longitude
- hacc/vacc: horizontal/vertical acceleration
- alt: altitude
- speed: self explanatory
- course: unsure
- t: start timestamp
- dt: end timestamp
- dist: distance (in kilometers, I think)
relv: relative velocity (maybe)
So essentially, by looking at the latitude and longitude and timestamp, you can figure out where you were at what time. It’s a little bit tedious to do so (if you’re trying to upload an old file), however you can avoid this if it’s your most recent activity.
4. My Strava refused to upload this file (also, it had a timestamp in the past), so I’m guessing that somewhere on your mobile device strava marks certain events that you decide not to upload and skips over them when the app boots up.
To work around this limitation, I simply recorded a new activity and brought myself to the screen before the “save” screen.


Don’t hit “save” yet.
You can see in iTunes that a new file was generated with the correct timestamp. I next clicked “Save to …” to copy this to my local machine, where I brought it up in sublime again. Note the UUID (DF5…857A831ECFD) looking thing so you can locate the file after you copy it locally.

The file looks like this (note how small it is since we only recorded about 9seconds worth; also maybe interesting, Strava filling up your phone maybe @ 0.5 – 1KB/second means that each hour of activity is very roughly few MB, probably depends on the # of breaks you take):
lvseg: t:485562945.972006 on:1
strt: t:485562945.983277
wp: lat:37.338599; long:-121.978195; hacc:10.000000; vacc:32.000000; alt:54.916534; speed:0.620000; course:-1.000000; t:1463870147.006819; dt:1463870147.006819; dist:0.000000
wp: lat:37.338570; long:-121.978124; hacc:10.000000; vacc:12.000000; alt:42.931915; speed:0.000000; course:-1.000000; t:1463870148.002843; dt:1463870148.002843; dist:0.000000
relv: v:0.000000; t:1463870148.671240;
Next what I did is copy the contents of the original file into this file, essentially deleting everything in this file after the “strt: t:485562945.983277”. Not sure if this is strictly necessary, but at any rate, it probably doesn’t hurt.
5. Finally, the last step is to copy the modified file (with the same filename) back to iTunes. iTunes will prompt you for whether you want to overwrite the file. Hit “Replace”.
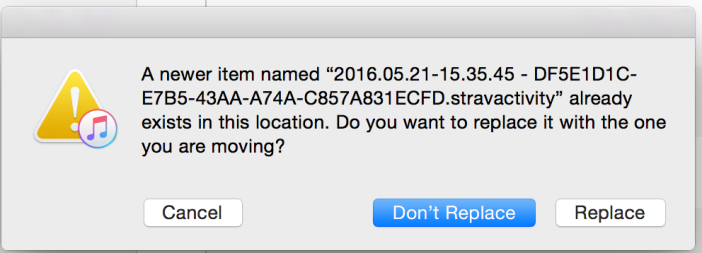
Now you’ll see that the file changes size on your iPhone.

8. Now you can hit “save” on your Strava app. If you did everything right, you’ll see that the activity gets uploaded and parsed by Strava’s servers. If it’s a large file, it may take some time.
That’s it! Your precious stats are back.
Note to Strava developers: you can probably encrypt these files rather than store them in plaintext. I’m not saying I would ever mess with the GPS coordinates or timestamps to hack my way to King of the Mountain status or anything, but others might. 😉